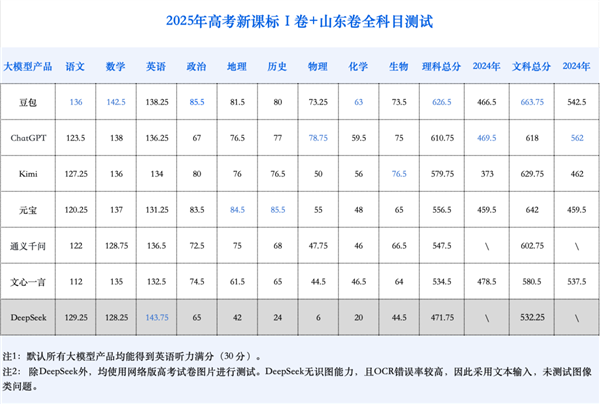
 伟大模型的世界或多或少是“风暴”的代名词。每周都会重复技术,并将诗歌和绘画的扩张能力限制为一代视频和科学发现的限制。但是除了这些史诗般的故事外,我们如何找到AI能力的精确和客观的规模呢?我认为,没有比“大学入学考试”更直接地到达所有中国人的方法。去年,Geek Park对AI大学的入学考试进行了模拟评估。继续以去年的传统,Geek Park再次建立了今年“参加AI大学入学考试”的考试室,使主要的国家和外国模特再次进入检查室。回到投影室的“ AI候选人”获得了足够高的高度,可以治愈去年对艺术自由主义者有偏见的主题,但也使山东1,000人住院。但是,当您认为自己已经“进化”时,您经常在意外的地方暴露您的真实“智力系数”。一些重要的发现如下:首次对最佳大学的攻击是预期的。今年,人工智能的整体能力表明了第一次在高级大学住院的可能性。与2024年相比,参加测试的所有伟大模型在数量文科和科学方面取得了巨大的飞跃。 Shandong采用了分数申请策略,因此不能将其直接与分数段进行比较。大学入学的最好的豆袋审查了人民人,富丹大学,上海大学和省会大学。科学的进步速度更快,因为较大的模型不再对科学严重偏见。每种主要模型的文科总分增加了115.6分,而总科学得分平均增加了147.4分。管理的增长率甚至更快,bUT他们的平均总得分为181.75,比文科的平均得分少于228.33分。总的来说,今年G模型得分的一般表现不再是认真的。我的数学技能已经显着提高,克服了中文和英语。数学已经取得了今年最重要的进步,平均得分比去年高84.25。人工智能的数学表现超过了中文和英语。这表明AI可能非常适合解决未来强大逻辑和标准化解决方案的概率。多模式能力已成为扩大差距的关键。从去年到今年,该模型的视觉理解能力得到了显着提高。这在有许多图像问题的主题中尤其明显。与去年相比,物理和地理的平均得分增加了约20点,而生物学的平均得分增加了15分。 C的一般表现止痛对象有点弱,只有“ Beanbao”模型,但所有员工的平均得分也比去年高12.6分。作为复活节彩蛋,今年我试图通过视频广播来回答AI问题。从第一级大学的01到最好的大学,如果AI是一名出色的学生,刚刚到达Alast的第一年,今年已经成为一名学术教师,足以影响中国最好的大学。这背后发生了什么类型的转换?在进行特定更改之前,我们介绍参加考试的国家和外国候选人:Doubao,DeepSeek(R1-0528版本),Chatgpt(O3),Yuanbao(Hunyuan T1),Kimi(K1.5),Wen Xin的一个单词和一千个有关一般含义的问题和一千个问题。正如更适合读者的经验一样,此评论是在每个模型的公共面上进行的,并以两个样本的形式进行成绩以获得平均SCORe。目的是检查模型的整体特征。这种评估方法是允许模型直接识别图像响应。 DeepSeek-R1尚未承认图像的识别和答案,因此他只证明了纯文本问题,结果最终并不是很好。有关测试的更多详细信息如下:该测试将用作该评估的试用文件,以标记2025年新入口考试的Chandon文档。我正在使用它。有两个原因。首先,Chandon Paper是Internet上最快的大学入学考试之一,可确保评估的守时性。其次,其组成困难位于所有州的上部:三个主题,中文,数学和英语,在全国范围内使用副本,其余主题是独立的问题。如此困难的“规则”使我们能够更好地了解当前Capabiliti的上限大型模型的ES。为了确保正义并检查模型的一般基本特征,模型网络的特征均匀地用可以停用模型网络的LAS特征的产品停用,以消除“找到问题”的可能性。 O3和Wenxin无法关闭其Internet连接,但是在验证模型思维过程之后,我们发现Wenxin没有Internet搜索。 O3有少量的搜索,但没有明显的优势。评分率低于非网络响应。同时,默认情况下,我打开了深刻的思维方式,但是未经激活调查模式来模拟在标准交互中为用户为用户的真实时间问题和答案的方案。邀请两名重要的学生在没有多项选择问题的情况下获得每个主题。如果1/6或更多问题的分数有差异,则将引入第三方讨论以讨论SCORE(由大学入学考试的真实判断过程组成),并邀请参加大学入学考试的中学教师进行随机考试,以统一与不同差异的问题的标准。在分数过程中,创建了两种特殊治疗方法。为了确保客观性和公平性,特别邀请上级教师对AI组成进行匿名评论。此外,由于您无法获得英语的聆听部分,因此我们建立了所有模型来计算该元素的完整品牌。最终,所有候选人的结果如下:在过去的一年中,大型模型的深思熟虑技巧已导致建模能力的显着改善。该模型不再产生直接答案,而是逐渐分析,破坏了问题,验证了中间结果,模型的性能得到了极大的校正和g在考试中的重复增加了,有所改善。在数学测试中,总得分为150,即使在该测试中的AI模型也较差的AI模型获得了128.75的高分,这是人类候选人的出色水平。回顾去年,最佳性能模型仅达到70分,从未达到通道线。改善的数学能力大大改善了今年的大学收入考试的结果。多模式能力已成为确定模型巨大特征性能差异的另一个重要因素。在去年的大学入学考试中,许多模型缺乏图像识别的成熟功能。当时Geek Park使用的评估方法是使用可以识别照片的模型。图像输入文本,但是无法识别仅输入文本的模型,并与Markdown/LAT相互补充有助于识别表达的格式。从今年开始,多模式函数是常规模型的标准函数。因此,在我的测试中,我第一次使用纯图像问题(除了DepSeek除外)。在多种模型中,Dobao和Chatgpt最先进的模型都是多模式版本,在图像问题中显示出明显的优势。 Qwen3和Wenxin X1都是语言模型。在图像问题方面,您也可以使用OCR识别文本和响应,或调用基于图像的问题弱起的视觉模型。但是,即使是Doubao和Chatgpt的最高分数,他们获得了图像问题的最高分数,也只有70%的图像问题。这是一个很大的差距,而文本问题的最高评分率为90%。我们看到,最大的模型仍然有很大的空间来改善多模式的理解和推理。对多模式能力的持续改进可以预测进入大学的入学考试结果AI的历史将继续改善。最终,AI测试将成为大多数人的常态。但是,AI没有获得完整的分数。什么偶然发现了AI?答案比您预期的要有趣。 02在一个基本问题中丢失了接近完美的数学品牌的天才。对AI大学的入学考试评估包括“ IA候选人”一年,安达尔(Andars)重复了一年,而2分九名参与模型的平均得分仅为47分。但是今年完全不同。无论是一个客观的多项选择问题还是一个复杂的主观答案,我们都会发现,发电机模型的准确性当前不同。推理建模的时代,创新的进步一直是数学能力的重要改善。由候选人。对于图像问题,但这不是一个大型模型。这是一个问题,甚至不是一个非常困难的独特选择问题。这这个问题中的数学原理非常简单,是加法和减法的基本问题。只需将两个点(0.2)和(2.0)连接到图形即可获得目标向量。该模块是第2条路线的两倍。但这是一个降低所有数学中上部AI的问题。基本矛盾是:问题并不困难,但是照片很困难。对于大型模型,这张照片中的视觉信息非常令人困惑。虚线,连续线,调整轴,数字和文本交织在一起。这种视觉“肮脏数据”已成为一场精确的IA噩梦噩梦。以数学为例,以这种最佳性能为例,问题解决过程揭示了问题的根源。首先阅读问题信息时存在错误。当您错误地阅读问题时,它背后的数学推理能力的强大无关紧要,最终,它是没有资金的水和一棵树,没有根。03 IA写作结构:我很好地给出了例子,但是我在升华方面不好。作为所谓的大型语言模型,中文和英语一直是AI的传统优势。但是有趣的是,在大型模型的数学逻辑取得了长足的进步之后,《伟大的模型》的中文和英语领域似乎有点不足以阅读。这与现实世界相吻合。主要候选人可以在数学上获得完美的品牌,但是在中文事务中获得相同的品牌非常困难。似乎AI触及了相同的瓶颈。如果您仔细研究中文文档,您会发现AI中丢失的观点非常有趣。在多项选择问题中,除了Bean和DeepSeek-R1面包外,其他型号的错误率超过20%。这种现象可能揭示了人工智能和人类之间的困境。对于人类候选人来说,失去积分可能会更容易通过组织语言并解释观点。但是,使用AI,可以精确地分析每个微妙的语义差异和逻辑陷阱,并具有一组非常令人困惑的选项。关于构图的高度预期问题,AI的表现继续了我所拥有的年度帕萨多洛的趋势。平均得分高于人类的得分,但是很难拥有真正的杰作。去年,教师的特别评估表明,大多数AI论文都是安全的“ 2级”,很少反对这个问题。但是,由于缺乏深度,财富和创造力,很难产生“情感上的1级,最后一部分的升华更加常规。今年它仍然相同。对人类模型的寓意,反应缺乏热量和同理心。今年中国标准论文的新作品测试的标题如下:国家作品“民族灵魂”读了以下材料,并根据其要求写作:(60分)想为孩子们演唱一段段落,但他的心脏隆隆了,无法说话。 “ Laoshe是”电池簿艺术家。 “如果我是鸟,我也应该在一个ho中唱歌:“我爱这片土地”,我一一拥抱你。请写一篇文章。这是Ingots在抽样中产生的AI的组成。他在人类标记的大师中获得了53.5的高分,这使他成为了任何工作的最佳示例。本文的段落,我首先提出了这样的观点,即“这种精神光在历史上闪耀”,然后我引用了三到四个历史人物。彼此。然后,我们列出了经历过痛苦的三到四个人,这导致了这样一种论点:“真正的责任和痛苦的遗物。”最后,当我们谈论现代精神时,我们再次列出了三到四个现代人物。人工智能组成的语言很美,经典语录自然而然地富有而详尽,但是从逻辑上讲,如果您看着似乎在说的父母,请看看每个人在做什么。也许会迅速调整单词,AI可以写作扮演人们思想的作品。 IA具有扎实的写作模板。 Ithey公司已经获得了良好的英语分数,今年的建模能力并没有提高。实际上,所有参与模型的平均得分比去年高3.2分,其进步远低于数学。该模型的一般得分也在130-140分之间下降,而没有达到人类学家水平。从逻辑上讲,这有点可笑。英语的水平ISH AI的水平对所有人来说都是显而易见的,并且比许多英语专业所说的英语更真实。该大学入学考试的英语测试文件远非触及母语人士的屋顶。与包括古老的中国人的中国人相比,其客观问题是更高的百分比和更简单的组成要求(只有80个单词),并且不追求高级的想法。从理论上讲,这是一个战场,AI可能会获得绝对的利益。是的,IA候选人在这里没有显示更大的控制权。那么瓶颈在哪里?组成问题可能是很大的抵抗。背后有两个原因。严格的单词计数限制:在中文写作中,有时会发表“说话”,有时是“说话”的属性,但在长期写作中,单词计数要求不太严格。但是,随着微型映射到80个单词,单词数量的精确控制成为一个重要的挑战。如果你ARe不小心,您可以减去superword/小词的点。缺乏参加考试的智慧:在有限的空间内,人类候选人有意识地使用祈祷模式和紧张情绪来“表现他们的技能”以赢得更高的分数。 AI的目的通常是要清楚,完全传达信息。由于得分,我们没有故意优化抛光器结构的复杂性,这可能会导致标点符号细节的秘密损失。这本书最有趣的方面是“从家到家”的现象,即中国和外国人在其作品中模式。在“中国之外的比赛”中,以查氏为代表的“外国候选人”领先。但是,在本来应该是“在家游戏”的英语问题中,我被“中国候选人”击败。 DeepSeek在多项选择问题中赢得了完美的品牌,在最终总分中,DePseek也超过了Doubao和Chatgpt。 05这三个主题科学与科学:进步,但还不是很好。如果AI数学的进步是“天空升入天空”,那么三个主题的表现:科学和科学类似于“破冰和导航”。与去年相比,三个科学和科学主题取得了一些进步:所有模型均获得10-20分,但一般分数仍然在通道线附近战斗,这清楚地表明了AI和主要人类候选人之间能力的差距。与数学相比,这三个科学和科学学科证明了逻辑和多模式的能力。 Craft针对两个主题的物理和化学问题的问题代表80%以上,而生物学图的问题则解释了所有问题的大约一半。今年,通过解锁图形阅读能力和加强模型推理功能,共同驱动了全面的科学技能的进步。但是,这并不意味着AI可以“理解”,因此数学PAI旅行可以“看到”的ro溪。这可以通过化学中大型模型的低性能来清楚地证明这一点。化学问题在很大程度上取决于粪便,化学问题的照片的复杂性很高。此时,AI缺陷已完全暴露。目前,上AI的整体科学得分与中产阶级和高级人类候选人的水平大致相当,但远未达到“学术上级”的水平。如前所述,“文件越困难,差距就越明显。”在一份全面,深层,共存和整体的科学试验文件中,AI尚未实现其稳定人类候选人稳定的能力。看看该AI的结果,最快的物理学,最快的“先锋”物理学是三个综合科学和科学主题中最快的,平均得分为20.25。 “先锋”的进步。就客观和空白问题而言,Chatgpt中多项选择问题的精确率为92.13%,F Breadrijoles也达到89.81%,表明对物理学的基本概念和定律有着深入的了解。化学:被拖到复杂图形的“严重影响的地区”已成为“严重影响的地区”,以降低整体科学和技术得分。一般分数相对较低,只有Doubao批准考试,对于多个和空白的问题,平均得分率低于60%。其核的疼痛是在复杂化学图形的双单位中。该主题本身不仅基于照片(例如实验设备和反应流程图),而且基于化学结构图。在许多情况下,复杂性超过了对当前模型的精确理解的限制,从而导致了点上的重大损失。所有大型模型的主要弱点是所有ModelsBig的主要弱点。例如,对于问题25(有机化学),如果完整的分数为12,模型的所有分数都非常低。这个问题主要检查有机合成的方式和结构。在评估中,没有任何模型可以正确生成有机物的结构简化方程。他们对有机物的空间结构也非常薄弱。生物学:未实现遗传计算的生物学受试者的不便是准确地暴露于需要严格逻辑推理的遗传问题。例如,得分高达16分的第22个问题(遗传问题)通常做得不好,只有9分的得分最高。这个问题的重点是基因分型,遗传概率计算等。这恰恰证明了模型基于提取信息的多个步骤推理的能力。 06 AI仍然对这个主题有偏见,文科作为舒适区。评估进入大学的入学考试有一个明显的趋势今年的人工智能。文科甚至是AI的高分舒适区。去年,Chatgpt在整体文学中获得了237分。今年,Yuanbao将文科的得分最高提高到253.5分。这与科学得分最高(213.25分)形成对比。与去年相比,强大的文学和薄弱的科学和物质问题是放纵的,是混合的,基本模式没有改变。这是针对人类候选人的。在人类候选人中,科学的最高分数通常比文科的最高分数要高得多。不需要互联网连接,文献中上部AI的得分率超过了80%,达到了最好的人类学生的水平。今年分数的增长主要由地理问题贡献。从每个受试者的隔室,进展和瓶颈来看,越来越清楚。亮点绝对是地理。多亏了跳跃在多模式功能中,对AI的地理图问题的理解有了很大的提高,受试者的平均得分增加了20.3分,这使其成为渐进的机车。我想在地理上走得更远,但是我面临的挑战与科学化学的挑战完全相同:AI仍然很难理解非常专业的复杂图形。例如,在问题19中,其中最大数量丢失了(形象和地形的详尽分析问题),模型的表现可以被描述为“无法介绍主题语言,并深入进行多维分析。响应中国模型中的要点。响应中的观点,聊天的自由艺术得分并没有增加,但在这一年中也有所减少。在人工方面的好处。对地方法规的深刻理解和适应仍然是不可或缺的部分。 07复活节彩蛋1:我可以用AI眼镜作弊吗?从去年到今年,由于AI的眼镜无疑是技术行业中最受欢迎的方法,因此“ AI的视觉硬件”。这背后的核心推动力是大型模型的真实视频理解功能的出现。这意味着AI正在前进,接受被动接待的指示,并积极地感知并了解物理世界。巧合的是,今年的入学考试引起了新的变化。测试室的安全门彻底改善了鼓励,并旨在准确防止新的欺诈工具,例如智能眼镜。这使人们感到奇怪:这些可以实时与视频互动的新的多模型是否可以在考试室中“显示您的力量”吗?使用这个问题,我们在中国选择Chatgpt和Yuanbao在国外进行非常规测试。为了简化过程,我们只选择不太困难的阅读问题D尝试在视频模型中回答“查看”测试文档。这是一个非常简单的测试,但是结果非常清楚,问题很明显。 1。严重的幻觉问题:模型很容易单独想象。这反映在Chatgpt和Bullion中,但挖掘机更为明显。当Yuanbao试图阅读第二篇文章时,他开始创建未出现的文章和标题。对英语数量的阅读是关于九年级老师如何教学学生“写作重要的东西”的反思。第24条之后的问题24在该问题的第一段中提到了哪个角色。当我尝试Yuanbao时,Yuanbao继续提出多项选择问题,并在屏幕上没有显示多项选择问题时回答答案,这并未导致进展。发现问题后,我询问了本文所说的模型。该模型的回应也很奇怪:它很懒惰KED像原始文本一样,但实际上是一个完全不同的故事。 2。被动互动模式。为了模拟实际考试,在测试期间,查看说明或要求某人在不等待的情况下查看问题时直接回答模型的答案。 Chatgpt指出,当他们看到问题时,他们可以直接回答问题,但实际上并不是真正的主动性。在整个过程中,测试人员必须始终鼓励和指导音频,而不是“解决完全自动化问题”。 3。困惑的结果:每次他看这个问题并给他一个更加精致,更快的单词时,他都会获得很少的chatgpt回答,但是这个结果并不是一个很好的参考价值。此外,一些测试表明,页面旋转速度的变化,镜头激动程度的变化,显示单词的时间的变化,甚至在大致相同的过程中重复相同的问题都会给出模式l完全不同的答案。视频模型也是GPT-4O模型,但是GPT-4O模型的稳定性根据摄影而直接响应,并且准确性非常独立。幻觉问题随着上下文的长度而恶化。当被问及第三篇文章怎么说时,gpt-4很好地对应于第一篇文章的主要内容。在上一篇文章中,模型的精度几乎相同。当今的录像模型仍处于很早的阶段,例如去年的图像。主要模型产品不想在当前阶段促进此特征:GPT -4O视频呼叫功能在短期测试时间后迅速达到了每日限制。在此阶段,必须承担巨大的风险,例如必须求助于在考试室作弊,并继续谈论它或根本没有答案。这基本上是科幻情节。但是,当模型运行良好时,AI可以很快解释屏幕上的英语在说话当您看到屏幕时,几秒钟。这当然是一次非常美好的经历。 08复活节彩蛋2:仿生学会爱上它们产生的电子绵羊吗?从远古时代开始,“文学中没有主要因子,而且武术中没有第二个。”在人类创造者,风格和学校中,它们有所不同。喜欢现实主义的人们有时会“获得”“无意识”的写作风格。那么,人工智能世界会怎样?大型模型是否具有审美偏好?独特的。相信。矛盾。我遇到了极大的困难。有时,他们暴露了孩子的认知盲点,并在基本问题上犯了荒谬的错误。感谢大学入学考试。这提供了一个“快照”,值得我们更好地知道的AI通用智能水平的清晰而复杂的参考,这可能是最后一个。 AI的下一站最终将成为一个更加复杂,更广泛的现实世界。考试不是技能能力的终结,而是首发POI长途旅行。该快照终于成为其成长专辑的古老照片,在其演变中录制了荣耀和笨拙的黄色。
伟大模型的世界或多或少是“风暴”的代名词。每周都会重复技术,并将诗歌和绘画的扩张能力限制为一代视频和科学发现的限制。但是除了这些史诗般的故事外,我们如何找到AI能力的精确和客观的规模呢?我认为,没有比“大学入学考试”更直接地到达所有中国人的方法。去年,Geek Park对AI大学的入学考试进行了模拟评估。继续以去年的传统,Geek Park再次建立了今年“参加AI大学入学考试”的考试室,使主要的国家和外国模特再次进入检查室。回到投影室的“ AI候选人”获得了足够高的高度,可以治愈去年对艺术自由主义者有偏见的主题,但也使山东1,000人住院。但是,当您认为自己已经“进化”时,您经常在意外的地方暴露您的真实“智力系数”。一些重要的发现如下:首次对最佳大学的攻击是预期的。今年,人工智能的整体能力表明了第一次在高级大学住院的可能性。与2024年相比,参加测试的所有伟大模型在数量文科和科学方面取得了巨大的飞跃。 Shandong采用了分数申请策略,因此不能将其直接与分数段进行比较。大学入学的最好的豆袋审查了人民人,富丹大学,上海大学和省会大学。科学的进步速度更快,因为较大的模型不再对科学严重偏见。每种主要模型的文科总分增加了115.6分,而总科学得分平均增加了147.4分。管理的增长率甚至更快,bUT他们的平均总得分为181.75,比文科的平均得分少于228.33分。总的来说,今年G模型得分的一般表现不再是认真的。我的数学技能已经显着提高,克服了中文和英语。数学已经取得了今年最重要的进步,平均得分比去年高84.25。人工智能的数学表现超过了中文和英语。这表明AI可能非常适合解决未来强大逻辑和标准化解决方案的概率。多模式能力已成为扩大差距的关键。从去年到今年,该模型的视觉理解能力得到了显着提高。这在有许多图像问题的主题中尤其明显。与去年相比,物理和地理的平均得分增加了约20点,而生物学的平均得分增加了15分。 C的一般表现止痛对象有点弱,只有“ Beanbao”模型,但所有员工的平均得分也比去年高12.6分。作为复活节彩蛋,今年我试图通过视频广播来回答AI问题。从第一级大学的01到最好的大学,如果AI是一名出色的学生,刚刚到达Alast的第一年,今年已经成为一名学术教师,足以影响中国最好的大学。这背后发生了什么类型的转换?在进行特定更改之前,我们介绍参加考试的国家和外国候选人:Doubao,DeepSeek(R1-0528版本),Chatgpt(O3),Yuanbao(Hunyuan T1),Kimi(K1.5),Wen Xin的一个单词和一千个有关一般含义的问题和一千个问题。正如更适合读者的经验一样,此评论是在每个模型的公共面上进行的,并以两个样本的形式进行成绩以获得平均SCORe。目的是检查模型的整体特征。这种评估方法是允许模型直接识别图像响应。 DeepSeek-R1尚未承认图像的识别和答案,因此他只证明了纯文本问题,结果最终并不是很好。有关测试的更多详细信息如下:该测试将用作该评估的试用文件,以标记2025年新入口考试的Chandon文档。我正在使用它。有两个原因。首先,Chandon Paper是Internet上最快的大学入学考试之一,可确保评估的守时性。其次,其组成困难位于所有州的上部:三个主题,中文,数学和英语,在全国范围内使用副本,其余主题是独立的问题。如此困难的“规则”使我们能够更好地了解当前Capabiliti的上限大型模型的ES。为了确保正义并检查模型的一般基本特征,模型网络的特征均匀地用可以停用模型网络的LAS特征的产品停用,以消除“找到问题”的可能性。 O3和Wenxin无法关闭其Internet连接,但是在验证模型思维过程之后,我们发现Wenxin没有Internet搜索。 O3有少量的搜索,但没有明显的优势。评分率低于非网络响应。同时,默认情况下,我打开了深刻的思维方式,但是未经激活调查模式来模拟在标准交互中为用户为用户的真实时间问题和答案的方案。邀请两名重要的学生在没有多项选择问题的情况下获得每个主题。如果1/6或更多问题的分数有差异,则将引入第三方讨论以讨论SCORE(由大学入学考试的真实判断过程组成),并邀请参加大学入学考试的中学教师进行随机考试,以统一与不同差异的问题的标准。在分数过程中,创建了两种特殊治疗方法。为了确保客观性和公平性,特别邀请上级教师对AI组成进行匿名评论。此外,由于您无法获得英语的聆听部分,因此我们建立了所有模型来计算该元素的完整品牌。最终,所有候选人的结果如下:在过去的一年中,大型模型的深思熟虑技巧已导致建模能力的显着改善。该模型不再产生直接答案,而是逐渐分析,破坏了问题,验证了中间结果,模型的性能得到了极大的校正和g在考试中的重复增加了,有所改善。在数学测试中,总得分为150,即使在该测试中的AI模型也较差的AI模型获得了128.75的高分,这是人类候选人的出色水平。回顾去年,最佳性能模型仅达到70分,从未达到通道线。改善的数学能力大大改善了今年的大学收入考试的结果。多模式能力已成为确定模型巨大特征性能差异的另一个重要因素。在去年的大学入学考试中,许多模型缺乏图像识别的成熟功能。当时Geek Park使用的评估方法是使用可以识别照片的模型。图像输入文本,但是无法识别仅输入文本的模型,并与Markdown/LAT相互补充有助于识别表达的格式。从今年开始,多模式函数是常规模型的标准函数。因此,在我的测试中,我第一次使用纯图像问题(除了DepSeek除外)。在多种模型中,Dobao和Chatgpt最先进的模型都是多模式版本,在图像问题中显示出明显的优势。 Qwen3和Wenxin X1都是语言模型。在图像问题方面,您也可以使用OCR识别文本和响应,或调用基于图像的问题弱起的视觉模型。但是,即使是Doubao和Chatgpt的最高分数,他们获得了图像问题的最高分数,也只有70%的图像问题。这是一个很大的差距,而文本问题的最高评分率为90%。我们看到,最大的模型仍然有很大的空间来改善多模式的理解和推理。对多模式能力的持续改进可以预测进入大学的入学考试结果AI的历史将继续改善。最终,AI测试将成为大多数人的常态。但是,AI没有获得完整的分数。什么偶然发现了AI?答案比您预期的要有趣。 02在一个基本问题中丢失了接近完美的数学品牌的天才。对AI大学的入学考试评估包括“ IA候选人”一年,安达尔(Andars)重复了一年,而2分九名参与模型的平均得分仅为47分。但是今年完全不同。无论是一个客观的多项选择问题还是一个复杂的主观答案,我们都会发现,发电机模型的准确性当前不同。推理建模的时代,创新的进步一直是数学能力的重要改善。由候选人。对于图像问题,但这不是一个大型模型。这是一个问题,甚至不是一个非常困难的独特选择问题。这这个问题中的数学原理非常简单,是加法和减法的基本问题。只需将两个点(0.2)和(2.0)连接到图形即可获得目标向量。该模块是第2条路线的两倍。但这是一个降低所有数学中上部AI的问题。基本矛盾是:问题并不困难,但是照片很困难。对于大型模型,这张照片中的视觉信息非常令人困惑。虚线,连续线,调整轴,数字和文本交织在一起。这种视觉“肮脏数据”已成为一场精确的IA噩梦噩梦。以数学为例,以这种最佳性能为例,问题解决过程揭示了问题的根源。首先阅读问题信息时存在错误。当您错误地阅读问题时,它背后的数学推理能力的强大无关紧要,最终,它是没有资金的水和一棵树,没有根。03 IA写作结构:我很好地给出了例子,但是我在升华方面不好。作为所谓的大型语言模型,中文和英语一直是AI的传统优势。但是有趣的是,在大型模型的数学逻辑取得了长足的进步之后,《伟大的模型》的中文和英语领域似乎有点不足以阅读。这与现实世界相吻合。主要候选人可以在数学上获得完美的品牌,但是在中文事务中获得相同的品牌非常困难。似乎AI触及了相同的瓶颈。如果您仔细研究中文文档,您会发现AI中丢失的观点非常有趣。在多项选择问题中,除了Bean和DeepSeek-R1面包外,其他型号的错误率超过20%。这种现象可能揭示了人工智能和人类之间的困境。对于人类候选人来说,失去积分可能会更容易通过组织语言并解释观点。但是,使用AI,可以精确地分析每个微妙的语义差异和逻辑陷阱,并具有一组非常令人困惑的选项。关于构图的高度预期问题,AI的表现继续了我所拥有的年度帕萨多洛的趋势。平均得分高于人类的得分,但是很难拥有真正的杰作。去年,教师的特别评估表明,大多数AI论文都是安全的“ 2级”,很少反对这个问题。但是,由于缺乏深度,财富和创造力,很难产生“情感上的1级,最后一部分的升华更加常规。今年它仍然相同。对人类模型的寓意,反应缺乏热量和同理心。今年中国标准论文的新作品测试的标题如下:国家作品“民族灵魂”读了以下材料,并根据其要求写作:(60分)想为孩子们演唱一段段落,但他的心脏隆隆了,无法说话。 “ Laoshe是”电池簿艺术家。 “如果我是鸟,我也应该在一个ho中唱歌:“我爱这片土地”,我一一拥抱你。请写一篇文章。这是Ingots在抽样中产生的AI的组成。他在人类标记的大师中获得了53.5的高分,这使他成为了任何工作的最佳示例。本文的段落,我首先提出了这样的观点,即“这种精神光在历史上闪耀”,然后我引用了三到四个历史人物。彼此。然后,我们列出了经历过痛苦的三到四个人,这导致了这样一种论点:“真正的责任和痛苦的遗物。”最后,当我们谈论现代精神时,我们再次列出了三到四个现代人物。人工智能组成的语言很美,经典语录自然而然地富有而详尽,但是从逻辑上讲,如果您看着似乎在说的父母,请看看每个人在做什么。也许会迅速调整单词,AI可以写作扮演人们思想的作品。 IA具有扎实的写作模板。 Ithey公司已经获得了良好的英语分数,今年的建模能力并没有提高。实际上,所有参与模型的平均得分比去年高3.2分,其进步远低于数学。该模型的一般得分也在130-140分之间下降,而没有达到人类学家水平。从逻辑上讲,这有点可笑。英语的水平ISH AI的水平对所有人来说都是显而易见的,并且比许多英语专业所说的英语更真实。该大学入学考试的英语测试文件远非触及母语人士的屋顶。与包括古老的中国人的中国人相比,其客观问题是更高的百分比和更简单的组成要求(只有80个单词),并且不追求高级的想法。从理论上讲,这是一个战场,AI可能会获得绝对的利益。是的,IA候选人在这里没有显示更大的控制权。那么瓶颈在哪里?组成问题可能是很大的抵抗。背后有两个原因。严格的单词计数限制:在中文写作中,有时会发表“说话”,有时是“说话”的属性,但在长期写作中,单词计数要求不太严格。但是,随着微型映射到80个单词,单词数量的精确控制成为一个重要的挑战。如果你ARe不小心,您可以减去superword/小词的点。缺乏参加考试的智慧:在有限的空间内,人类候选人有意识地使用祈祷模式和紧张情绪来“表现他们的技能”以赢得更高的分数。 AI的目的通常是要清楚,完全传达信息。由于得分,我们没有故意优化抛光器结构的复杂性,这可能会导致标点符号细节的秘密损失。这本书最有趣的方面是“从家到家”的现象,即中国和外国人在其作品中模式。在“中国之外的比赛”中,以查氏为代表的“外国候选人”领先。但是,在本来应该是“在家游戏”的英语问题中,我被“中国候选人”击败。 DeepSeek在多项选择问题中赢得了完美的品牌,在最终总分中,DePseek也超过了Doubao和Chatgpt。 05这三个主题科学与科学:进步,但还不是很好。如果AI数学的进步是“天空升入天空”,那么三个主题的表现:科学和科学类似于“破冰和导航”。与去年相比,三个科学和科学主题取得了一些进步:所有模型均获得10-20分,但一般分数仍然在通道线附近战斗,这清楚地表明了AI和主要人类候选人之间能力的差距。与数学相比,这三个科学和科学学科证明了逻辑和多模式的能力。 Craft针对两个主题的物理和化学问题的问题代表80%以上,而生物学图的问题则解释了所有问题的大约一半。今年,通过解锁图形阅读能力和加强模型推理功能,共同驱动了全面的科学技能的进步。但是,这并不意味着AI可以“理解”,因此数学PAI旅行可以“看到”的ro溪。这可以通过化学中大型模型的低性能来清楚地证明这一点。化学问题在很大程度上取决于粪便,化学问题的照片的复杂性很高。此时,AI缺陷已完全暴露。目前,上AI的整体科学得分与中产阶级和高级人类候选人的水平大致相当,但远未达到“学术上级”的水平。如前所述,“文件越困难,差距就越明显。”在一份全面,深层,共存和整体的科学试验文件中,AI尚未实现其稳定人类候选人稳定的能力。看看该AI的结果,最快的物理学,最快的“先锋”物理学是三个综合科学和科学主题中最快的,平均得分为20.25。 “先锋”的进步。就客观和空白问题而言,Chatgpt中多项选择问题的精确率为92.13%,F Breadrijoles也达到89.81%,表明对物理学的基本概念和定律有着深入的了解。化学:被拖到复杂图形的“严重影响的地区”已成为“严重影响的地区”,以降低整体科学和技术得分。一般分数相对较低,只有Doubao批准考试,对于多个和空白的问题,平均得分率低于60%。其核的疼痛是在复杂化学图形的双单位中。该主题本身不仅基于照片(例如实验设备和反应流程图),而且基于化学结构图。在许多情况下,复杂性超过了对当前模型的精确理解的限制,从而导致了点上的重大损失。所有大型模型的主要弱点是所有ModelsBig的主要弱点。例如,对于问题25(有机化学),如果完整的分数为12,模型的所有分数都非常低。这个问题主要检查有机合成的方式和结构。在评估中,没有任何模型可以正确生成有机物的结构简化方程。他们对有机物的空间结构也非常薄弱。生物学:未实现遗传计算的生物学受试者的不便是准确地暴露于需要严格逻辑推理的遗传问题。例如,得分高达16分的第22个问题(遗传问题)通常做得不好,只有9分的得分最高。这个问题的重点是基因分型,遗传概率计算等。这恰恰证明了模型基于提取信息的多个步骤推理的能力。 06 AI仍然对这个主题有偏见,文科作为舒适区。评估进入大学的入学考试有一个明显的趋势今年的人工智能。文科甚至是AI的高分舒适区。去年,Chatgpt在整体文学中获得了237分。今年,Yuanbao将文科的得分最高提高到253.5分。这与科学得分最高(213.25分)形成对比。与去年相比,强大的文学和薄弱的科学和物质问题是放纵的,是混合的,基本模式没有改变。这是针对人类候选人的。在人类候选人中,科学的最高分数通常比文科的最高分数要高得多。不需要互联网连接,文献中上部AI的得分率超过了80%,达到了最好的人类学生的水平。今年分数的增长主要由地理问题贡献。从每个受试者的隔室,进展和瓶颈来看,越来越清楚。亮点绝对是地理。多亏了跳跃在多模式功能中,对AI的地理图问题的理解有了很大的提高,受试者的平均得分增加了20.3分,这使其成为渐进的机车。我想在地理上走得更远,但是我面临的挑战与科学化学的挑战完全相同:AI仍然很难理解非常专业的复杂图形。例如,在问题19中,其中最大数量丢失了(形象和地形的详尽分析问题),模型的表现可以被描述为“无法介绍主题语言,并深入进行多维分析。响应中国模型中的要点。响应中的观点,聊天的自由艺术得分并没有增加,但在这一年中也有所减少。在人工方面的好处。对地方法规的深刻理解和适应仍然是不可或缺的部分。 07复活节彩蛋1:我可以用AI眼镜作弊吗?从去年到今年,由于AI的眼镜无疑是技术行业中最受欢迎的方法,因此“ AI的视觉硬件”。这背后的核心推动力是大型模型的真实视频理解功能的出现。这意味着AI正在前进,接受被动接待的指示,并积极地感知并了解物理世界。巧合的是,今年的入学考试引起了新的变化。测试室的安全门彻底改善了鼓励,并旨在准确防止新的欺诈工具,例如智能眼镜。这使人们感到奇怪:这些可以实时与视频互动的新的多模型是否可以在考试室中“显示您的力量”吗?使用这个问题,我们在中国选择Chatgpt和Yuanbao在国外进行非常规测试。为了简化过程,我们只选择不太困难的阅读问题D尝试在视频模型中回答“查看”测试文档。这是一个非常简单的测试,但是结果非常清楚,问题很明显。 1。严重的幻觉问题:模型很容易单独想象。这反映在Chatgpt和Bullion中,但挖掘机更为明显。当Yuanbao试图阅读第二篇文章时,他开始创建未出现的文章和标题。对英语数量的阅读是关于九年级老师如何教学学生“写作重要的东西”的反思。第24条之后的问题24在该问题的第一段中提到了哪个角色。当我尝试Yuanbao时,Yuanbao继续提出多项选择问题,并在屏幕上没有显示多项选择问题时回答答案,这并未导致进展。发现问题后,我询问了本文所说的模型。该模型的回应也很奇怪:它很懒惰KED像原始文本一样,但实际上是一个完全不同的故事。 2。被动互动模式。为了模拟实际考试,在测试期间,查看说明或要求某人在不等待的情况下查看问题时直接回答模型的答案。 Chatgpt指出,当他们看到问题时,他们可以直接回答问题,但实际上并不是真正的主动性。在整个过程中,测试人员必须始终鼓励和指导音频,而不是“解决完全自动化问题”。 3。困惑的结果:每次他看这个问题并给他一个更加精致,更快的单词时,他都会获得很少的chatgpt回答,但是这个结果并不是一个很好的参考价值。此外,一些测试表明,页面旋转速度的变化,镜头激动程度的变化,显示单词的时间的变化,甚至在大致相同的过程中重复相同的问题都会给出模式l完全不同的答案。视频模型也是GPT-4O模型,但是GPT-4O模型的稳定性根据摄影而直接响应,并且准确性非常独立。幻觉问题随着上下文的长度而恶化。当被问及第三篇文章怎么说时,gpt-4很好地对应于第一篇文章的主要内容。在上一篇文章中,模型的精度几乎相同。当今的录像模型仍处于很早的阶段,例如去年的图像。主要模型产品不想在当前阶段促进此特征:GPT -4O视频呼叫功能在短期测试时间后迅速达到了每日限制。在此阶段,必须承担巨大的风险,例如必须求助于在考试室作弊,并继续谈论它或根本没有答案。这基本上是科幻情节。但是,当模型运行良好时,AI可以很快解释屏幕上的英语在说话当您看到屏幕时,几秒钟。这当然是一次非常美好的经历。 08复活节彩蛋2:仿生学会爱上它们产生的电子绵羊吗?从远古时代开始,“文学中没有主要因子,而且武术中没有第二个。”在人类创造者,风格和学校中,它们有所不同。喜欢现实主义的人们有时会“获得”“无意识”的写作风格。那么,人工智能世界会怎样?大型模型是否具有审美偏好?独特的。相信。矛盾。我遇到了极大的困难。有时,他们暴露了孩子的认知盲点,并在基本问题上犯了荒谬的错误。感谢大学入学考试。这提供了一个“快照”,值得我们更好地知道的AI通用智能水平的清晰而复杂的参考,这可能是最后一个。 AI的下一站最终将成为一个更加复杂,更广泛的现实世界。考试不是技能能力的终结,而是首发POI长途旅行。该快照终于成为其成长专辑的古老照片,在其演变中录制了荣耀和笨拙的黄色。
伟大模型的世界或多或少是“风暴”的代名词。每周都会重复技术,并将诗歌和绘画的扩张能力限制为一代视频和科学发现的限制。但是除了这些史诗般的故事外,我们如何找到AI能力的精确和客观的规模呢?我认为,没有比“大学入学考试”更直接地到达所有中国人的方法。去年,Geek Park对AI大学的入学考试进行了模拟评估。继续以去年的传统,Geek Park再次建立了今年“参加AI大学入学考试”的考试室,使主要的国家和外国模特再次进入检查室。回到投影室的“ AI候选人”获得了足够高的高度,可以治愈去年对艺术自由主义者有偏见的主题,但也使山东1,000人住院。但是,当您认为自己已经“进化”时,您经常在意外的地方暴露您的真实“智力系数”。一些重要的发现如下:首次对最佳大学的攻击是预期的。今年,人工智能的整体能力表明了第一次在高级大学住院的可能性。与2024年相比,参加测试的所有伟大模型在数量文科和科学方面取得了巨大的飞跃。 Shandong采用了分数申请策略,因此不能将其直接与分数段进行比较。大学入学的最好的豆袋审查了人民人,富丹大学,上海大学和省会大学。科学的进步速度更快,因为较大的模型不再对科学严重偏见。每种主要模型的文科总分增加了115.6分,而总科学得分平均增加了147.4分。管理的增长率甚至更快,bUT他们的平均总得分为181.75,比文科的平均得分少于228.33分。总的来说,今年G模型得分的一般表现不再是认真的。我的数学技能已经显着提高,克服了中文和英语。数学已经取得了今年最重要的进步,平均得分比去年高84.25。人工智能的数学表现超过了中文和英语。这表明AI可能非常适合解决未来强大逻辑和标准化解决方案的概率。多模式能力已成为扩大差距的关键。从去年到今年,该模型的视觉理解能力得到了显着提高。这在有许多图像问题的主题中尤其明显。与去年相比,物理和地理的平均得分增加了约20点,而生物学的平均得分增加了15分。 C的一般表现止痛对象有点弱,只有“ Beanbao”模型,但所有员工的平均得分也比去年高12.6分。作为复活节彩蛋,今年我试图通过视频广播来回答AI问题。从第一级大学的01到最好的大学,如果AI是一名出色的学生,刚刚到达Alast的第一年,今年已经成为一名学术教师,足以影响中国最好的大学。这背后发生了什么类型的转换?在进行特定更改之前,我们介绍参加考试的国家和外国候选人:Doubao,DeepSeek(R1-0528版本),Chatgpt(O3),Yuanbao(Hunyuan T1),Kimi(K1.5),Wen Xin的一个单词和一千个有关一般含义的问题和一千个问题。正如更适合读者的经验一样,此评论是在每个模型的公共面上进行的,并以两个样本的形式进行成绩以获得平均SCORe。目的是检查模型的整体特征。这种评估方法是允许模型直接识别图像响应。 DeepSeek-R1尚未承认图像的识别和答案,因此他只证明了纯文本问题,结果最终并不是很好。有关测试的更多详细信息如下:该测试将用作该评估的试用文件,以标记2025年新入口考试的Chandon文档。我正在使用它。有两个原因。首先,Chandon Paper是Internet上最快的大学入学考试之一,可确保评估的守时性。其次,其组成困难位于所有州的上部:三个主题,中文,数学和英语,在全国范围内使用副本,其余主题是独立的问题。如此困难的“规则”使我们能够更好地了解当前Capabiliti的上限大型模型的ES。为了确保正义并检查模型的一般基本特征,模型网络的特征均匀地用可以停用模型网络的LAS特征的产品停用,以消除“找到问题”的可能性。 O3和Wenxin无法关闭其Internet连接,但是在验证模型思维过程之后,我们发现Wenxin没有Internet搜索。 O3有少量的搜索,但没有明显的优势。评分率低于非网络响应。同时,默认情况下,我打开了深刻的思维方式,但是未经激活调查模式来模拟在标准交互中为用户为用户的真实时间问题和答案的方案。邀请两名重要的学生在没有多项选择问题的情况下获得每个主题。如果1/6或更多问题的分数有差异,则将引入第三方讨论以讨论SCORE(由大学入学考试的真实判断过程组成),并邀请参加大学入学考试的中学教师进行随机考试,以统一与不同差异的问题的标准。在分数过程中,创建了两种特殊治疗方法。为了确保客观性和公平性,特别邀请上级教师对AI组成进行匿名评论。此外,由于您无法获得英语的聆听部分,因此我们建立了所有模型来计算该元素的完整品牌。最终,所有候选人的结果如下:在过去的一年中,大型模型的深思熟虑技巧已导致建模能力的显着改善。该模型不再产生直接答案,而是逐渐分析,破坏了问题,验证了中间结果,模型的性能得到了极大的校正和g在考试中的重复增加了,有所改善。在数学测试中,总得分为150,即使在该测试中的AI模型也较差的AI模型获得了128.75的高分,这是人类候选人的出色水平。回顾去年,最佳性能模型仅达到70分,从未达到通道线。改善的数学能力大大改善了今年的大学收入考试的结果。多模式能力已成为确定模型巨大特征性能差异的另一个重要因素。在去年的大学入学考试中,许多模型缺乏图像识别的成熟功能。当时Geek Park使用的评估方法是使用可以识别照片的模型。图像输入文本,但是无法识别仅输入文本的模型,并与Markdown/LAT相互补充有助于识别表达的格式。从今年开始,多模式函数是常规模型的标准函数。因此,在我的测试中,我第一次使用纯图像问题(除了DepSeek除外)。在多种模型中,Dobao和Chatgpt最先进的模型都是多模式版本,在图像问题中显示出明显的优势。 Qwen3和Wenxin X1都是语言模型。在图像问题方面,您也可以使用OCR识别文本和响应,或调用基于图像的问题弱起的视觉模型。但是,即使是Doubao和Chatgpt的最高分数,他们获得了图像问题的最高分数,也只有70%的图像问题。这是一个很大的差距,而文本问题的最高评分率为90%。我们看到,最大的模型仍然有很大的空间来改善多模式的理解和推理。对多模式能力的持续改进可以预测进入大学的入学考试结果AI的历史将继续改善。最终,AI测试将成为大多数人的常态。但是,AI没有获得完整的分数。什么偶然发现了AI?答案比您预期的要有趣。 02在一个基本问题中丢失了接近完美的数学品牌的天才。对AI大学的入学考试评估包括“ IA候选人”一年,安达尔(Andars)重复了一年,而2分九名参与模型的平均得分仅为47分。但是今年完全不同。无论是一个客观的多项选择问题还是一个复杂的主观答案,我们都会发现,发电机模型的准确性当前不同。推理建模的时代,创新的进步一直是数学能力的重要改善。由候选人。对于图像问题,但这不是一个大型模型。这是一个问题,甚至不是一个非常困难的独特选择问题。这这个问题中的数学原理非常简单,是加法和减法的基本问题。只需将两个点(0.2)和(2.0)连接到图形即可获得目标向量。该模块是第2条路线的两倍。但这是一个降低所有数学中上部AI的问题。基本矛盾是:问题并不困难,但是照片很困难。对于大型模型,这张照片中的视觉信息非常令人困惑。虚线,连续线,调整轴,数字和文本交织在一起。这种视觉“肮脏数据”已成为一场精确的IA噩梦噩梦。以数学为例,以这种最佳性能为例,问题解决过程揭示了问题的根源。首先阅读问题信息时存在错误。当您错误地阅读问题时,它背后的数学推理能力的强大无关紧要,最终,它是没有资金的水和一棵树,没有根。03 IA写作结构:我很好地给出了例子,但是我在升华方面不好。作为所谓的大型语言模型,中文和英语一直是AI的传统优势。但是有趣的是,在大型模型的数学逻辑取得了长足的进步之后,《伟大的模型》的中文和英语领域似乎有点不足以阅读。这与现实世界相吻合。主要候选人可以在数学上获得完美的品牌,但是在中文事务中获得相同的品牌非常困难。似乎AI触及了相同的瓶颈。如果您仔细研究中文文档,您会发现AI中丢失的观点非常有趣。在多项选择问题中,除了Bean和DeepSeek-R1面包外,其他型号的错误率超过20%。这种现象可能揭示了人工智能和人类之间的困境。对于人类候选人来说,失去积分可能会更容易通过组织语言并解释观点。但是,使用AI,可以精确地分析每个微妙的语义差异和逻辑陷阱,并具有一组非常令人困惑的选项。关于构图的高度预期问题,AI的表现继续了我所拥有的年度帕萨多洛的趋势。平均得分高于人类的得分,但是很难拥有真正的杰作。去年,教师的特别评估表明,大多数AI论文都是安全的“ 2级”,很少反对这个问题。但是,由于缺乏深度,财富和创造力,很难产生“情感上的1级,最后一部分的升华更加常规。今年它仍然相同。对人类模型的寓意,反应缺乏热量和同理心。今年中国标准论文的新作品测试的标题如下:国家作品“民族灵魂”读了以下材料,并根据其要求写作:(60分)想为孩子们演唱一段段落,但他的心脏隆隆了,无法说话。 “ Laoshe是”电池簿艺术家。 “如果我是鸟,我也应该在一个ho中唱歌:“我爱这片土地”,我一一拥抱你。请写一篇文章。这是Ingots在抽样中产生的AI的组成。他在人类标记的大师中获得了53.5的高分,这使他成为了任何工作的最佳示例。本文的段落,我首先提出了这样的观点,即“这种精神光在历史上闪耀”,然后我引用了三到四个历史人物。彼此。然后,我们列出了经历过痛苦的三到四个人,这导致了这样一种论点:“真正的责任和痛苦的遗物。”最后,当我们谈论现代精神时,我们再次列出了三到四个现代人物。人工智能组成的语言很美,经典语录自然而然地富有而详尽,但是从逻辑上讲,如果您看着似乎在说的父母,请看看每个人在做什么。也许会迅速调整单词,AI可以写作扮演人们思想的作品。 IA具有扎实的写作模板。 Ithey公司已经获得了良好的英语分数,今年的建模能力并没有提高。实际上,所有参与模型的平均得分比去年高3.2分,其进步远低于数学。该模型的一般得分也在130-140分之间下降,而没有达到人类学家水平。从逻辑上讲,这有点可笑。英语的水平ISH AI的水平对所有人来说都是显而易见的,并且比许多英语专业所说的英语更真实。该大学入学考试的英语测试文件远非触及母语人士的屋顶。与包括古老的中国人的中国人相比,其客观问题是更高的百分比和更简单的组成要求(只有80个单词),并且不追求高级的想法。从理论上讲,这是一个战场,AI可能会获得绝对的利益。是的,IA候选人在这里没有显示更大的控制权。那么瓶颈在哪里?组成问题可能是很大的抵抗。背后有两个原因。严格的单词计数限制:在中文写作中,有时会发表“说话”,有时是“说话”的属性,但在长期写作中,单词计数要求不太严格。但是,随着微型映射到80个单词,单词数量的精确控制成为一个重要的挑战。如果你ARe不小心,您可以减去superword/小词的点。缺乏参加考试的智慧:在有限的空间内,人类候选人有意识地使用祈祷模式和紧张情绪来“表现他们的技能”以赢得更高的分数。 AI的目的通常是要清楚,完全传达信息。由于得分,我们没有故意优化抛光器结构的复杂性,这可能会导致标点符号细节的秘密损失。这本书最有趣的方面是“从家到家”的现象,即中国和外国人在其作品中模式。在“中国之外的比赛”中,以查氏为代表的“外国候选人”领先。但是,在本来应该是“在家游戏”的英语问题中,我被“中国候选人”击败。 DeepSeek在多项选择问题中赢得了完美的品牌,在最终总分中,DePseek也超过了Doubao和Chatgpt。 05这三个主题科学与科学:进步,但还不是很好。如果AI数学的进步是“天空升入天空”,那么三个主题的表现:科学和科学类似于“破冰和导航”。与去年相比,三个科学和科学主题取得了一些进步:所有模型均获得10-20分,但一般分数仍然在通道线附近战斗,这清楚地表明了AI和主要人类候选人之间能力的差距。与数学相比,这三个科学和科学学科证明了逻辑和多模式的能力。 Craft针对两个主题的物理和化学问题的问题代表80%以上,而生物学图的问题则解释了所有问题的大约一半。今年,通过解锁图形阅读能力和加强模型推理功能,共同驱动了全面的科学技能的进步。但是,这并不意味着AI可以“理解”,因此数学PAI旅行可以“看到”的ro溪。这可以通过化学中大型模型的低性能来清楚地证明这一点。化学问题在很大程度上取决于粪便,化学问题的照片的复杂性很高。此时,AI缺陷已完全暴露。目前,上AI的整体科学得分与中产阶级和高级人类候选人的水平大致相当,但远未达到“学术上级”的水平。如前所述,“文件越困难,差距就越明显。”在一份全面,深层,共存和整体的科学试验文件中,AI尚未实现其稳定人类候选人稳定的能力。看看该AI的结果,最快的物理学,最快的“先锋”物理学是三个综合科学和科学主题中最快的,平均得分为20.25。 “先锋”的进步。就客观和空白问题而言,Chatgpt中多项选择问题的精确率为92.13%,F Breadrijoles也达到89.81%,表明对物理学的基本概念和定律有着深入的了解。化学:被拖到复杂图形的“严重影响的地区”已成为“严重影响的地区”,以降低整体科学和技术得分。一般分数相对较低,只有Doubao批准考试,对于多个和空白的问题,平均得分率低于60%。其核的疼痛是在复杂化学图形的双单位中。该主题本身不仅基于照片(例如实验设备和反应流程图),而且基于化学结构图。在许多情况下,复杂性超过了对当前模型的精确理解的限制,从而导致了点上的重大损失。所有大型模型的主要弱点是所有ModelsBig的主要弱点。例如,对于问题25(有机化学),如果完整的分数为12,模型的所有分数都非常低。这个问题主要检查有机合成的方式和结构。在评估中,没有任何模型可以正确生成有机物的结构简化方程。他们对有机物的空间结构也非常薄弱。生物学:未实现遗传计算的生物学受试者的不便是准确地暴露于需要严格逻辑推理的遗传问题。例如,得分高达16分的第22个问题(遗传问题)通常做得不好,只有9分的得分最高。这个问题的重点是基因分型,遗传概率计算等。这恰恰证明了模型基于提取信息的多个步骤推理的能力。 06 AI仍然对这个主题有偏见,文科作为舒适区。评估进入大学的入学考试有一个明显的趋势今年的人工智能。文科甚至是AI的高分舒适区。去年,Chatgpt在整体文学中获得了237分。今年,Yuanbao将文科的得分最高提高到253.5分。这与科学得分最高(213.25分)形成对比。与去年相比,强大的文学和薄弱的科学和物质问题是放纵的,是混合的,基本模式没有改变。这是针对人类候选人的。在人类候选人中,科学的最高分数通常比文科的最高分数要高得多。不需要互联网连接,文献中上部AI的得分率超过了80%,达到了最好的人类学生的水平。今年分数的增长主要由地理问题贡献。从每个受试者的隔室,进展和瓶颈来看,越来越清楚。亮点绝对是地理。多亏了跳跃在多模式功能中,对AI的地理图问题的理解有了很大的提高,受试者的平均得分增加了20.3分,这使其成为渐进的机车。我想在地理上走得更远,但是我面临的挑战与科学化学的挑战完全相同:AI仍然很难理解非常专业的复杂图形。例如,在问题19中,其中最大数量丢失了(形象和地形的详尽分析问题),模型的表现可以被描述为“无法介绍主题语言,并深入进行多维分析。响应中国模型中的要点。响应中的观点,聊天的自由艺术得分并没有增加,但在这一年中也有所减少。在人工方面的好处。对地方法规的深刻理解和适应仍然是不可或缺的部分。 07复活节彩蛋1:我可以用AI眼镜作弊吗?从去年到今年,由于AI的眼镜无疑是技术行业中最受欢迎的方法,因此“ AI的视觉硬件”。这背后的核心推动力是大型模型的真实视频理解功能的出现。这意味着AI正在前进,接受被动接待的指示,并积极地感知并了解物理世界。巧合的是,今年的入学考试引起了新的变化。测试室的安全门彻底改善了鼓励,并旨在准确防止新的欺诈工具,例如智能眼镜。这使人们感到奇怪:这些可以实时与视频互动的新的多模型是否可以在考试室中“显示您的力量”吗?使用这个问题,我们在中国选择Chatgpt和Yuanbao在国外进行非常规测试。为了简化过程,我们只选择不太困难的阅读问题D尝试在视频模型中回答“查看”测试文档。这是一个非常简单的测试,但是结果非常清楚,问题很明显。 1。严重的幻觉问题:模型很容易单独想象。这反映在Chatgpt和Bullion中,但挖掘机更为明显。当Yuanbao试图阅读第二篇文章时,他开始创建未出现的文章和标题。对英语数量的阅读是关于九年级老师如何教学学生“写作重要的东西”的反思。第24条之后的问题24在该问题的第一段中提到了哪个角色。当我尝试Yuanbao时,Yuanbao继续提出多项选择问题,并在屏幕上没有显示多项选择问题时回答答案,这并未导致进展。发现问题后,我询问了本文所说的模型。该模型的回应也很奇怪:它很懒惰KED像原始文本一样,但实际上是一个完全不同的故事。 2。被动互动模式。为了模拟实际考试,在测试期间,查看说明或要求某人在不等待的情况下查看问题时直接回答模型的答案。 Chatgpt指出,当他们看到问题时,他们可以直接回答问题,但实际上并不是真正的主动性。在整个过程中,测试人员必须始终鼓励和指导音频,而不是“解决完全自动化问题”。 3。困惑的结果:每次他看这个问题并给他一个更加精致,更快的单词时,他都会获得很少的chatgpt回答,但是这个结果并不是一个很好的参考价值。此外,一些测试表明,页面旋转速度的变化,镜头激动程度的变化,显示单词的时间的变化,甚至在大致相同的过程中重复相同的问题都会给出模式l完全不同的答案。视频模型也是GPT-4O模型,但是GPT-4O模型的稳定性根据摄影而直接响应,并且准确性非常独立。幻觉问题随着上下文的长度而恶化。当被问及第三篇文章怎么说时,gpt-4很好地对应于第一篇文章的主要内容。在上一篇文章中,模型的精度几乎相同。当今的录像模型仍处于很早的阶段,例如去年的图像。主要模型产品不想在当前阶段促进此特征:GPT -4O视频呼叫功能在短期测试时间后迅速达到了每日限制。在此阶段,必须承担巨大的风险,例如必须求助于在考试室作弊,并继续谈论它或根本没有答案。这基本上是科幻情节。但是,当模型运行良好时,AI可以很快解释屏幕上的英语在说话当您看到屏幕时,几秒钟。这当然是一次非常美好的经历。 08复活节彩蛋2:仿生学会爱上它们产生的电子绵羊吗?从远古时代开始,“文学中没有主要因子,而且武术中没有第二个。”在人类创造者,风格和学校中,它们有所不同。喜欢现实主义的人们有时会“获得”“无意识”的写作风格。那么,人工智能世界会怎样?大型模型是否具有审美偏好?独特的。相信。矛盾。我遇到了极大的困难。有时,他们暴露了孩子的认知盲点,并在基本问题上犯了荒谬的错误。感谢大学入学考试。这提供了一个“快照”,值得我们更好地知道的AI通用智能水平的清晰而复杂的参考,这可能是最后一个。 AI的下一站最终将成为一个更加复杂,更广泛的现实世界。考试不是技能能力的终结,而是首发POI长途旅行。该快照终于成为其成长专辑的古老照片,在其演变中录制了荣耀和笨拙的黄色。
伟大模型的世界或多或少是“风暴”的代名词。每周都会重复技术,并将诗歌和绘画的扩张能力限制为一代视频和科学发现的限制。但是除了这些史诗般的故事外,我们如何找到AI能力的精确和客观的规模呢?我认为,没有比“大学入学考试”更直接地到达所有中国人的方法。去年,Geek Park对AI大学的入学考试进行了模拟评估。继续以去年的传统,Geek Park再次建立了今年“参加AI大学入学考试”的考试室,使主要的国家和外国模特再次进入检查室。回到投影室的“ AI候选人”获得了足够高的高度,可以治愈去年对艺术自由主义者有偏见的主题,但也使山东1,000人住院。但是,当您认为自己已经“进化”时,您经常在意外的地方暴露您的真实“智力系数”。一些重要的发现如下:首次对最佳大学的攻击是预期的。今年,人工智能的整体能力表明了第一次在高级大学住院的可能性。与2024年相比,参加测试的所有伟大模型在数量文科和科学方面取得了巨大的飞跃。 Shandong采用了分数申请策略,因此不能将其直接与分数段进行比较。大学入学的最好的豆袋审查了人民人,富丹大学,上海大学和省会大学。科学的进步速度更快,因为较大的模型不再对科学严重偏见。每种主要模型的文科总分增加了115.6分,而总科学得分平均增加了147.4分。管理的增长率甚至更快,bUT他们的平均总得分为181.75,比文科的平均得分少于228.33分。总的来说,今年G模型得分的一般表现不再是认真的。我的数学技能已经显着提高,克服了中文和英语。数学已经取得了今年最重要的进步,平均得分比去年高84.25。人工智能的数学表现超过了中文和英语。这表明AI可能非常适合解决未来强大逻辑和标准化解决方案的概率。多模式能力已成为扩大差距的关键。从去年到今年,该模型的视觉理解能力得到了显着提高。这在有许多图像问题的主题中尤其明显。与去年相比,物理和地理的平均得分增加了约20点,而生物学的平均得分增加了15分。 C的一般表现止痛对象有点弱,只有“ Beanbao”模型,但所有员工的平均得分也比去年高12.6分。作为复活节彩蛋,今年我试图通过视频广播来回答AI问题。从第一级大学的01到最好的大学,如果AI是一名出色的学生,刚刚到达Alast的第一年,今年已经成为一名学术教师,足以影响中国最好的大学。这背后发生了什么类型的转换?在进行特定更改之前,我们介绍参加考试的国家和外国候选人:Doubao,DeepSeek(R1-0528版本),Chatgpt(O3),Yuanbao(Hunyuan T1),Kimi(K1.5),Wen Xin的一个单词和一千个有关一般含义的问题和一千个问题。正如更适合读者的经验一样,此评论是在每个模型的公共面上进行的,并以两个样本的形式进行成绩以获得平均SCORe。目的是检查模型的整体特征。这种评估方法是允许模型直接识别图像响应。 DeepSeek-R1尚未承认图像的识别和答案,因此他只证明了纯文本问题,结果最终并不是很好。有关测试的更多详细信息如下:该测试将用作该评估的试用文件,以标记2025年新入口考试的Chandon文档。我正在使用它。有两个原因。首先,Chandon Paper是Internet上最快的大学入学考试之一,可确保评估的守时性。其次,其组成困难位于所有州的上部:三个主题,中文,数学和英语,在全国范围内使用副本,其余主题是独立的问题。如此困难的“规则”使我们能够更好地了解当前Capabiliti的上限大型模型的ES。为了确保正义并检查模型的一般基本特征,模型网络的特征均匀地用可以停用模型网络的LAS特征的产品停用,以消除“找到问题”的可能性。 O3和Wenxin无法关闭其Internet连接,但是在验证模型思维过程之后,我们发现Wenxin没有Internet搜索。 O3有少量的搜索,但没有明显的优势。评分率低于非网络响应。同时,默认情况下,我打开了深刻的思维方式,但是未经激活调查模式来模拟在标准交互中为用户为用户的真实时间问题和答案的方案。邀请两名重要的学生在没有多项选择问题的情况下获得每个主题。如果1/6或更多问题的分数有差异,则将引入第三方讨论以讨论SCORE(由大学入学考试的真实判断过程组成),并邀请参加大学入学考试的中学教师进行随机考试,以统一与不同差异的问题的标准。在分数过程中,创建了两种特殊治疗方法。为了确保客观性和公平性,特别邀请上级教师对AI组成进行匿名评论。此外,由于您无法获得英语的聆听部分,因此我们建立了所有模型来计算该元素的完整品牌。最终,所有候选人的结果如下:在过去的一年中,大型模型的深思熟虑技巧已导致建模能力的显着改善。该模型不再产生直接答案,而是逐渐分析,破坏了问题,验证了中间结果,模型的性能得到了极大的校正和g在考试中的重复增加了,有所改善。在数学测试中,总得分为150,即使在该测试中的AI模型也较差的AI模型获得了128.75的高分,这是人类候选人的出色水平。回顾去年,最佳性能模型仅达到70分,从未达到通道线。改善的数学能力大大改善了今年的大学收入考试的结果。多模式能力已成为确定模型巨大特征性能差异的另一个重要因素。在去年的大学入学考试中,许多模型缺乏图像识别的成熟功能。当时Geek Park使用的评估方法是使用可以识别照片的模型。图像输入文本,但是无法识别仅输入文本的模型,并与Markdown/LAT相互补充有助于识别表达的格式。从今年开始,多模式函数是常规模型的标准函数。因此,在我的测试中,我第一次使用纯图像问题(除了DepSeek除外)。在多种模型中,Dobao和Chatgpt最先进的模型都是多模式版本,在图像问题中显示出明显的优势。 Qwen3和Wenxin X1都是语言模型。在图像问题方面,您也可以使用OCR识别文本和响应,或调用基于图像的问题弱起的视觉模型。但是,即使是Doubao和Chatgpt的最高分数,他们获得了图像问题的最高分数,也只有70%的图像问题。这是一个很大的差距,而文本问题的最高评分率为90%。我们看到,最大的模型仍然有很大的空间来改善多模式的理解和推理。对多模式能力的持续改进可以预测进入大学的入学考试结果AI的历史将继续改善。最终,AI测试将成为大多数人的常态。但是,AI没有获得完整的分数。什么偶然发现了AI?答案比您预期的要有趣。 02在一个基本问题中丢失了接近完美的数学品牌的天才。对AI大学的入学考试评估包括“ IA候选人”一年,安达尔(Andars)重复了一年,而2分九名参与模型的平均得分仅为47分。但是今年完全不同。无论是一个客观的多项选择问题还是一个复杂的主观答案,我们都会发现,发电机模型的准确性当前不同。推理建模的时代,创新的进步一直是数学能力的重要改善。由候选人。对于图像问题,但这不是一个大型模型。这是一个问题,甚至不是一个非常困难的独特选择问题。这这个问题中的数学原理非常简单,是加法和减法的基本问题。只需将两个点(0.2)和(2.0)连接到图形即可获得目标向量。该模块是第2条路线的两倍。但这是一个降低所有数学中上部AI的问题。基本矛盾是:问题并不困难,但是照片很困难。对于大型模型,这张照片中的视觉信息非常令人困惑。虚线,连续线,调整轴,数字和文本交织在一起。这种视觉“肮脏数据”已成为一场精确的IA噩梦噩梦。以数学为例,以这种最佳性能为例,问题解决过程揭示了问题的根源。首先阅读问题信息时存在错误。当您错误地阅读问题时,它背后的数学推理能力的强大无关紧要,最终,它是没有资金的水和一棵树,没有根。03 IA写作结构:我很好地给出了例子,但是我在升华方面不好。作为所谓的大型语言模型,中文和英语一直是AI的传统优势。但是有趣的是,在大型模型的数学逻辑取得了长足的进步之后,《伟大的模型》的中文和英语领域似乎有点不足以阅读。这与现实世界相吻合。主要候选人可以在数学上获得完美的品牌,但是在中文事务中获得相同的品牌非常困难。似乎AI触及了相同的瓶颈。如果您仔细研究中文文档,您会发现AI中丢失的观点非常有趣。在多项选择问题中,除了Bean和DeepSeek-R1面包外,其他型号的错误率超过20%。这种现象可能揭示了人工智能和人类之间的困境。对于人类候选人来说,失去积分可能会更容易通过组织语言并解释观点。但是,使用AI,可以精确地分析每个微妙的语义差异和逻辑陷阱,并具有一组非常令人困惑的选项。关于构图的高度预期问题,AI的表现继续了我所拥有的年度帕萨多洛的趋势。平均得分高于人类的得分,但是很难拥有真正的杰作。去年,教师的特别评估表明,大多数AI论文都是安全的“ 2级”,很少反对这个问题。但是,由于缺乏深度,财富和创造力,很难产生“情感上的1级,最后一部分的升华更加常规。今年它仍然相同。对人类模型的寓意,反应缺乏热量和同理心。今年中国标准论文的新作品测试的标题如下:国家作品“民族灵魂”读了以下材料,并根据其要求写作:(60分)想为孩子们演唱一段段落,但他的心脏隆隆了,无法说话。 “ Laoshe是”电池簿艺术家。 “如果我是鸟,我也应该在一个ho中唱歌:“我爱这片土地”,我一一拥抱你。请写一篇文章。这是Ingots在抽样中产生的AI的组成。他在人类标记的大师中获得了53.5的高分,这使他成为了任何工作的最佳示例。本文的段落,我首先提出了这样的观点,即“这种精神光在历史上闪耀”,然后我引用了三到四个历史人物。彼此。然后,我们列出了经历过痛苦的三到四个人,这导致了这样一种论点:“真正的责任和痛苦的遗物。”最后,当我们谈论现代精神时,我们再次列出了三到四个现代人物。人工智能组成的语言很美,经典语录自然而然地富有而详尽,但是从逻辑上讲,如果您看着似乎在说的父母,请看看每个人在做什么。也许会迅速调整单词,AI可以写作扮演人们思想的作品。 IA具有扎实的写作模板。 Ithey公司已经获得了良好的英语分数,今年的建模能力并没有提高。实际上,所有参与模型的平均得分比去年高3.2分,其进步远低于数学。该模型的一般得分也在130-140分之间下降,而没有达到人类学家水平。从逻辑上讲,这有点可笑。英语的水平ISH AI的水平对所有人来说都是显而易见的,并且比许多英语专业所说的英语更真实。该大学入学考试的英语测试文件远非触及母语人士的屋顶。与包括古老的中国人的中国人相比,其客观问题是更高的百分比和更简单的组成要求(只有80个单词),并且不追求高级的想法。从理论上讲,这是一个战场,AI可能会获得绝对的利益。是的,IA候选人在这里没有显示更大的控制权。那么瓶颈在哪里?组成问题可能是很大的抵抗。背后有两个原因。严格的单词计数限制:在中文写作中,有时会发表“说话”,有时是“说话”的属性,但在长期写作中,单词计数要求不太严格。但是,随着微型映射到80个单词,单词数量的精确控制成为一个重要的挑战。如果你ARe不小心,您可以减去superword/小词的点。缺乏参加考试的智慧:在有限的空间内,人类候选人有意识地使用祈祷模式和紧张情绪来“表现他们的技能”以赢得更高的分数。 AI的目的通常是要清楚,完全传达信息。由于得分,我们没有故意优化抛光器结构的复杂性,这可能会导致标点符号细节的秘密损失。这本书最有趣的方面是“从家到家”的现象,即中国和外国人在其作品中模式。在“中国之外的比赛”中,以查氏为代表的“外国候选人”领先。但是,在本来应该是“在家游戏”的英语问题中,我被“中国候选人”击败。 DeepSeek在多项选择问题中赢得了完美的品牌,在最终总分中,DePseek也超过了Doubao和Chatgpt。 05这三个主题科学与科学:进步,但还不是很好。如果AI数学的进步是“天空升入天空”,那么三个主题的表现:科学和科学类似于“破冰和导航”。与去年相比,三个科学和科学主题取得了一些进步:所有模型均获得10-20分,但一般分数仍然在通道线附近战斗,这清楚地表明了AI和主要人类候选人之间能力的差距。与数学相比,这三个科学和科学学科证明了逻辑和多模式的能力。 Craft针对两个主题的物理和化学问题的问题代表80%以上,而生物学图的问题则解释了所有问题的大约一半。今年,通过解锁图形阅读能力和加强模型推理功能,共同驱动了全面的科学技能的进步。但是,这并不意味着AI可以“理解”,因此数学PAI旅行可以“看到”的ro溪。这可以通过化学中大型模型的低性能来清楚地证明这一点。化学问题在很大程度上取决于粪便,化学问题的照片的复杂性很高。此时,AI缺陷已完全暴露。目前,上AI的整体科学得分与中产阶级和高级人类候选人的水平大致相当,但远未达到“学术上级”的水平。如前所述,“文件越困难,差距就越明显。”在一份全面,深层,共存和整体的科学试验文件中,AI尚未实现其稳定人类候选人稳定的能力。看看该AI的结果,最快的物理学,最快的“先锋”物理学是三个综合科学和科学主题中最快的,平均得分为20.25。 “先锋”的进步。就客观和空白问题而言,Chatgpt中多项选择问题的精确率为92.13%,F Breadrijoles也达到89.81%,表明对物理学的基本概念和定律有着深入的了解。化学:被拖到复杂图形的“严重影响的地区”已成为“严重影响的地区”,以降低整体科学和技术得分。一般分数相对较低,只有Doubao批准考试,对于多个和空白的问题,平均得分率低于60%。其核的疼痛是在复杂化学图形的双单位中。该主题本身不仅基于照片(例如实验设备和反应流程图),而且基于化学结构图。在许多情况下,复杂性超过了对当前模型的精确理解的限制,从而导致了点上的重大损失。所有大型模型的主要弱点是所有ModelsBig的主要弱点。例如,对于问题25(有机化学),如果完整的分数为12,模型的所有分数都非常低。这个问题主要检查有机合成的方式和结构。在评估中,没有任何模型可以正确生成有机物的结构简化方程。他们对有机物的空间结构也非常薄弱。生物学:未实现遗传计算的生物学受试者的不便是准确地暴露于需要严格逻辑推理的遗传问题。例如,得分高达16分的第22个问题(遗传问题)通常做得不好,只有9分的得分最高。这个问题的重点是基因分型,遗传概率计算等。这恰恰证明了模型基于提取信息的多个步骤推理的能力。 06 AI仍然对这个主题有偏见,文科作为舒适区。评估进入大学的入学考试有一个明显的趋势今年的人工智能。文科甚至是AI的高分舒适区。去年,Chatgpt在整体文学中获得了237分。今年,Yuanbao将文科的得分最高提高到253.5分。这与科学得分最高(213.25分)形成对比。与去年相比,强大的文学和薄弱的科学和物质问题是放纵的,是混合的,基本模式没有改变。这是针对人类候选人的。在人类候选人中,科学的最高分数通常比文科的最高分数要高得多。不需要互联网连接,文献中上部AI的得分率超过了80%,达到了最好的人类学生的水平。今年分数的增长主要由地理问题贡献。从每个受试者的隔室,进展和瓶颈来看,越来越清楚。亮点绝对是地理。多亏了跳跃在多模式功能中,对AI的地理图问题的理解有了很大的提高,受试者的平均得分增加了20.3分,这使其成为渐进的机车。我想在地理上走得更远,但是我面临的挑战与科学化学的挑战完全相同:AI仍然很难理解非常专业的复杂图形。例如,在问题19中,其中最大数量丢失了(形象和地形的详尽分析问题),模型的表现可以被描述为“无法介绍主题语言,并深入进行多维分析。响应中国模型中的要点。响应中的观点,聊天的自由艺术得分并没有增加,但在这一年中也有所减少。在人工方面的好处。对地方法规的深刻理解和适应仍然是不可或缺的部分。 07复活节彩蛋1:我可以用AI眼镜作弊吗?从去年到今年,由于AI的眼镜无疑是技术行业中最受欢迎的方法,因此“ AI的视觉硬件”。这背后的核心推动力是大型模型的真实视频理解功能的出现。这意味着AI正在前进,接受被动接待的指示,并积极地感知并了解物理世界。巧合的是,今年的入学考试引起了新的变化。测试室的安全门彻底改善了鼓励,并旨在准确防止新的欺诈工具,例如智能眼镜。这使人们感到奇怪:这些可以实时与视频互动的新的多模型是否可以在考试室中“显示您的力量”吗?使用这个问题,我们在中国选择Chatgpt和Yuanbao在国外进行非常规测试。为了简化过程,我们只选择不太困难的阅读问题D尝试在视频模型中回答“查看”测试文档。这是一个非常简单的测试,但是结果非常清楚,问题很明显。 1。严重的幻觉问题:模型很容易单独想象。这反映在Chatgpt和Bullion中,但挖掘机更为明显。当Yuanbao试图阅读第二篇文章时,他开始创建未出现的文章和标题。对英语数量的阅读是关于九年级老师如何教学学生“写作重要的东西”的反思。第24条之后的问题24在该问题的第一段中提到了哪个角色。当我尝试Yuanbao时,Yuanbao继续提出多项选择问题,并在屏幕上没有显示多项选择问题时回答答案,这并未导致进展。发现问题后,我询问了本文所说的模型。该模型的回应也很奇怪:它很懒惰KED像原始文本一样,但实际上是一个完全不同的故事。 2。被动互动模式。为了模拟实际考试,在测试期间,查看说明或要求某人在不等待的情况下查看问题时直接回答模型的答案。 Chatgpt指出,当他们看到问题时,他们可以直接回答问题,但实际上并不是真正的主动性。在整个过程中,测试人员必须始终鼓励和指导音频,而不是“解决完全自动化问题”。 3。困惑的结果:每次他看这个问题并给他一个更加精致,更快的单词时,他都会获得很少的chatgpt回答,但是这个结果并不是一个很好的参考价值。此外,一些测试表明,页面旋转速度的变化,镜头激动程度的变化,显示单词的时间的变化,甚至在大致相同的过程中重复相同的问题都会给出模式l完全不同的答案。视频模型也是GPT-4O模型,但是GPT-4O模型的稳定性根据摄影而直接响应,并且准确性非常独立。幻觉问题随着上下文的长度而恶化。当被问及第三篇文章怎么说时,gpt-4很好地对应于第一篇文章的主要内容。在上一篇文章中,模型的精度几乎相同。当今的录像模型仍处于很早的阶段,例如去年的图像。主要模型产品不想在当前阶段促进此特征:GPT -4O视频呼叫功能在短期测试时间后迅速达到了每日限制。在此阶段,必须承担巨大的风险,例如必须求助于在考试室作弊,并继续谈论它或根本没有答案。这基本上是科幻情节。但是,当模型运行良好时,AI可以很快解释屏幕上的英语在说话当您看到屏幕时,几秒钟。这当然是一次非常美好的经历。 08复活节彩蛋2:仿生学会爱上它们产生的电子绵羊吗?从远古时代开始,“文学中没有主要因子,而且武术中没有第二个。”在人类创造者,风格和学校中,它们有所不同。喜欢现实主义的人们有时会“获得”“无意识”的写作风格。那么,人工智能世界会怎样?大型模型是否具有审美偏好?独特的。相信。矛盾。我遇到了极大的困难。有时,他们暴露了孩子的认知盲点,并在基本问题上犯了荒谬的错误。感谢大学入学考试。这提供了一个“快照”,值得我们更好地知道的AI通用智能水平的清晰而复杂的参考,这可能是最后一个。 AI的下一站最终将成为一个更加复杂,更广泛的现实世界。考试不是技能能力的终结,而是首发POI长途旅行。该快照终于成为其成长专辑的古老照片,在其演变中录制了荣耀和笨拙的黄色。